Refined WaveNet Vocoder for Variational Autoencoder Based Voice Conversion
Demo page for paper: Refined WaveNet Vocoder for Variational Autoencoder Based Voice Conversion
Paper
Wen-Chin Huang, Yi-Chiao Wu, Hsin-Te Hwang, Patrick Lumban Tobing, Tomoki Hayashi, Kazuhiro Kobayashi, Tomoki Toda, Yu Tsao, Hsin-Min Wang, Refined WaveNet Vocoder for Variational Autoencoder Based Voice Conversion, arXiv preprint, Nov 2018
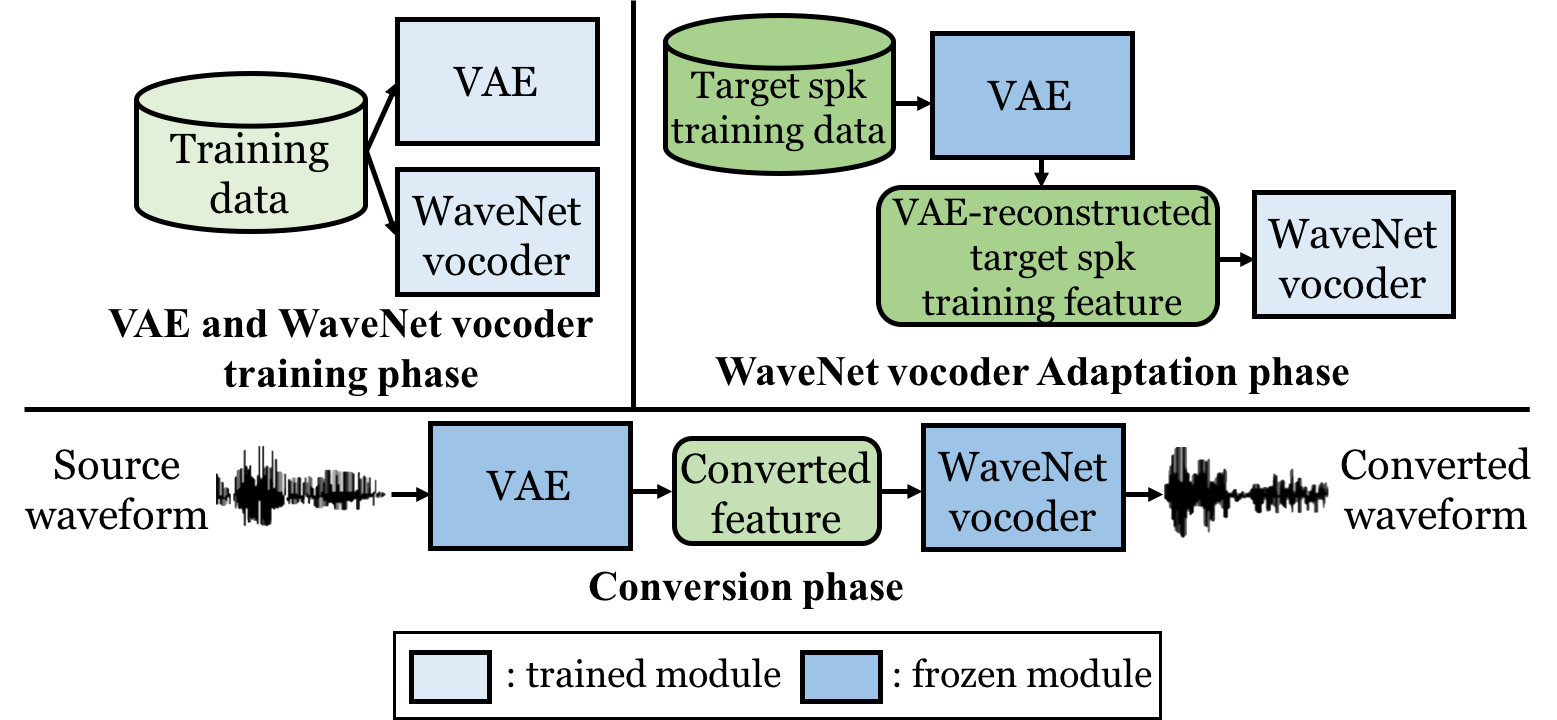
WaveNet vocoder adaptation via Variational Autoencoders
This paper presents a refinement framework of WaveNet vocoders for variational autoencoder (VAE) based voice conversion (VC), which reduces the quality distortion caused by the mismatch between the training data and testing data. Conventional WaveNet vocoders are trained with natural acoustic features but condition on the converted features in the conversion stage for VC, and such mismatch often causes significant quality and similarity degradation.
In this work, we take advantage of the particular structure of VAEs to refine WaveNet vocoders with the self-reconstructed features generated by VAE, which are of similar characteristics with the converted features while having the same data length with the target training data. In other words, our proposed method does not require any alignment.
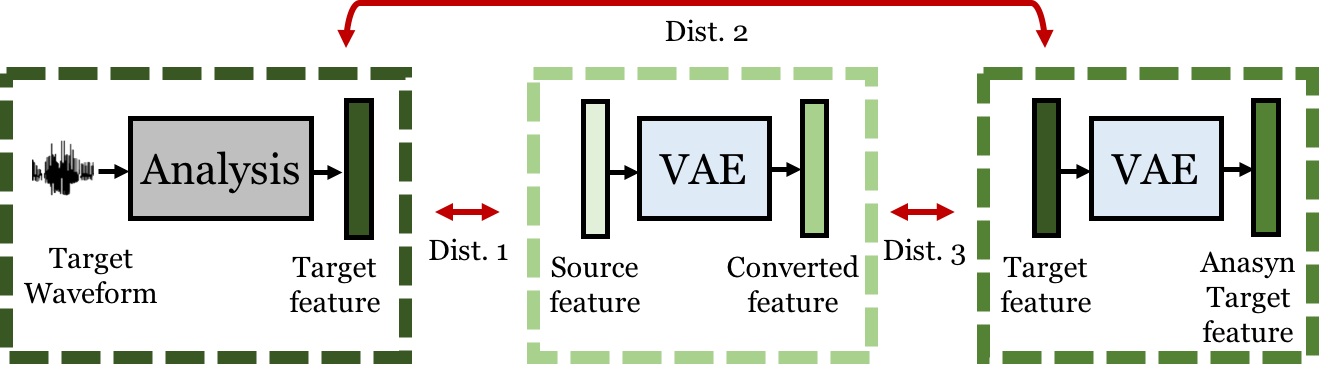
Analysis on distances
We calculated the MCDs of the natural and converted features (Dist. 1), VAE-reconstructed and natural features (Dist. 2), and VAE-reconstructed and converted features (Dist. 3). We observe that Dist. 2 is rather large, showing that the natural features are somehow distorted through the reconstruction process of VAE. We further observe that Dist. 3 is significantly smaller than Dist. 1, demonstrating that the VAE-reconstructed features are actually more similar to the converted features than the natural features in the Mel-cepstral domain.
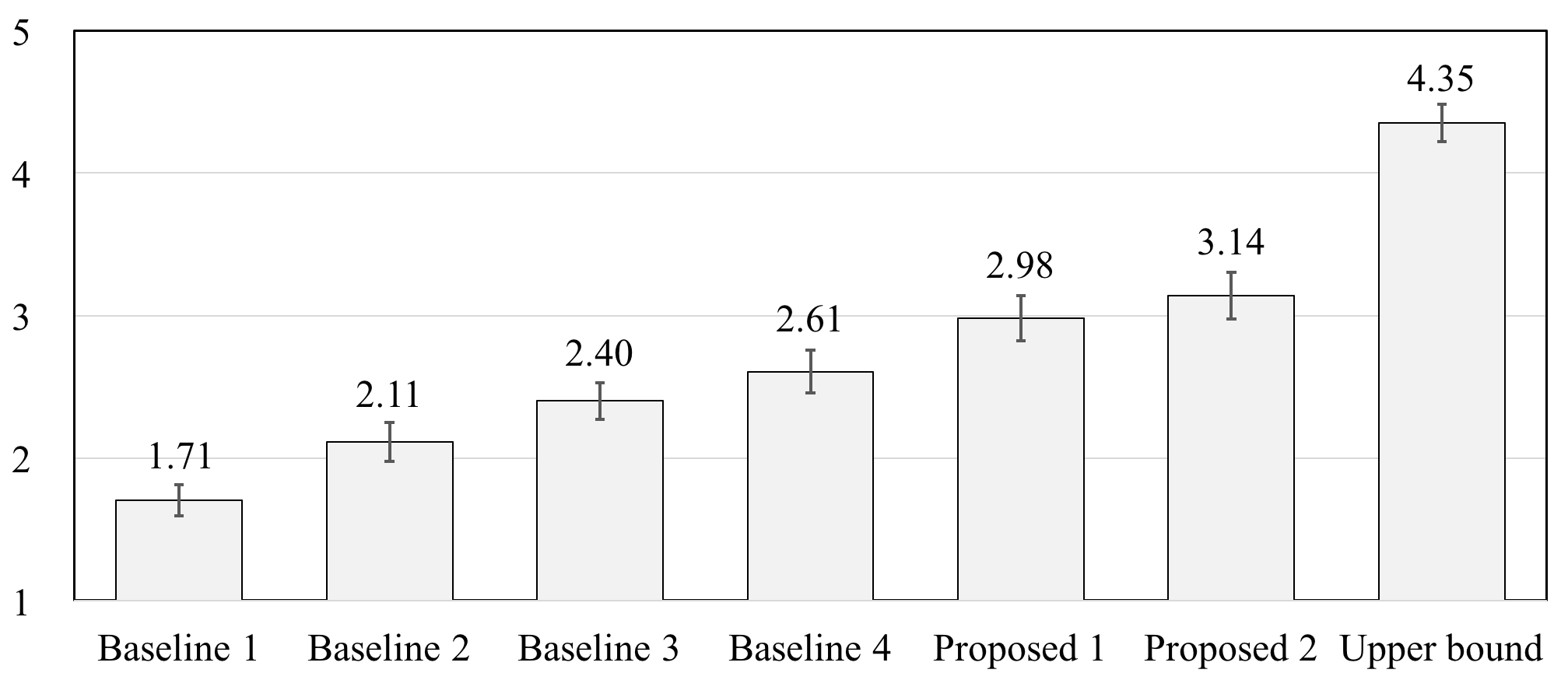
Subjective Evaluation Results
We evaluated our proposed framework on the Voice Conversion Challenge 2018 (VCC 2018) dataset. [Paper][Dataset]
Compared systems
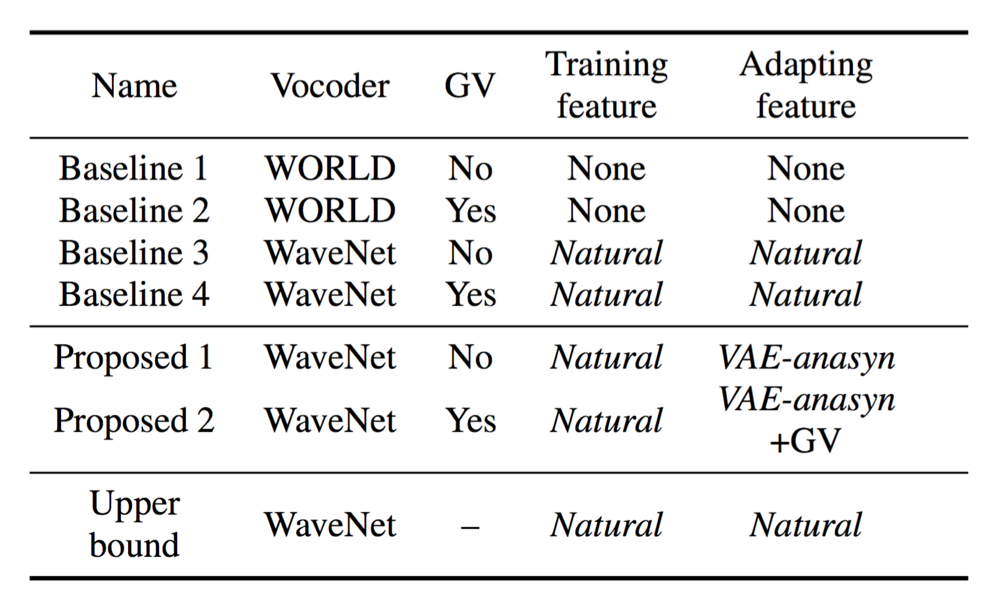
MOS on naturalness
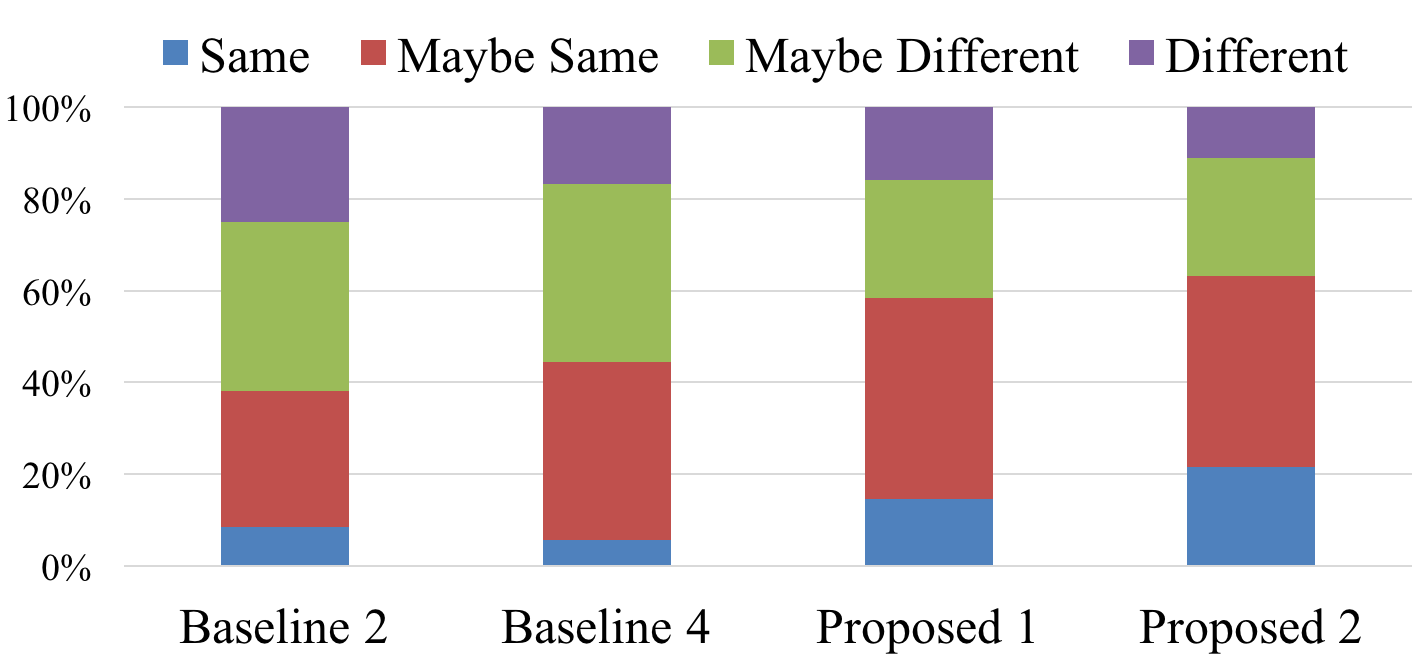
Conversion accuracy
Speech Samples
SF1-TF1
| Type | Sample |
|---|---|
| Source | |
| Target | |
| Baseline 1 | |
| Baseline 2 | |
| Baseline 3 | |
| Baseline 4 | |
| Proposed 1 | |
| Proposed 2 | |
| Upper bound |
SF1-TM1
| Type | Sample |
|---|---|
| Source | |
| Target | |
| Baseline 1 | |
| Baseline 2 | |
| Baseline 3 | |
| Baseline 4 | |
| Proposed 1 | |
| Proposed 2 | |
| Upper bound |