Abstract: We introduce a novel sequence-to-sequence (seq2seq) voice conversion (VC) model based on the Transformer architecture with text-to-speech (TTS) pre-training. Seq2seq VC models are attractive owing to their ability to convert prosody. While recurrent and convolutional based seq2seq models have been successfully applied to VC, the use of the Transformer network, which has shown promising results in various speech processing tasks, has not yet been investigated. Nonetheless, the data-hungry property and the mispronunciation in the converted speech make seq2seq models far from practical. To this end, we propose a simple yet effective pre-training technique to transfer knowledge from learned TTS models, which benefit from large scale, easily accessible TTS corpora. VC models initialized with such pre-trained model parameters are able to generate effective hidden representation for high-fidelity, highly intelligible converted speech. Experimental results show that such pre-training scheme can facilitate data efficient training, meanwhile outperform an RNN-based seq2seq VC model in terms of intelligibility, naturalness and similarity.
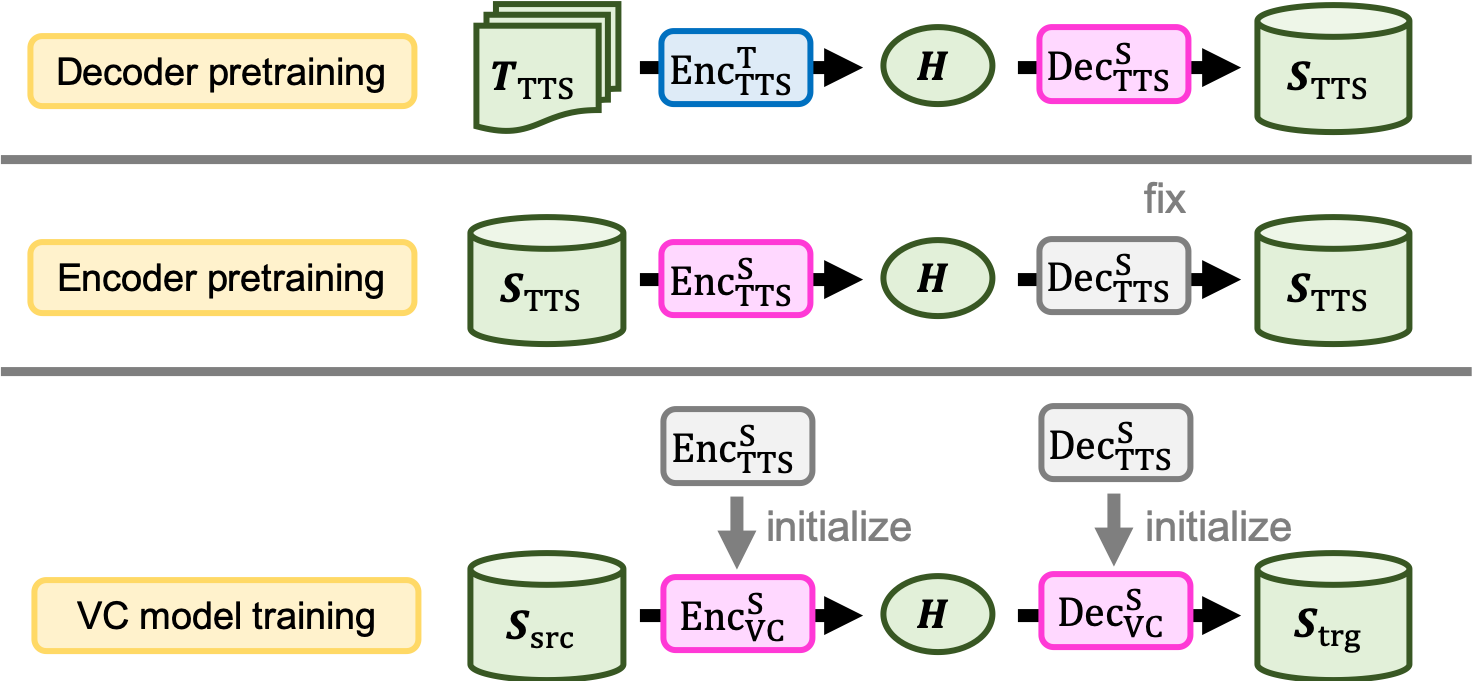
Proposed TTS pretraining
Dataset
We conducted all our experiments on the CMU Arctic database.
A male speaker (bdl) and a female speaker (clb) were chosen as source speakers, and a female speaker (slt) was chosen as the target speaker.
Models
Source, Target: Natural speech of the source and target speakers.
TTS adaptation: A Transformer-TTS model first pre-trained then adapted to the target speaker.