Authors: Wen-Chin Huang & Bence Mark Halpern (equal contribution), Lester Phillip Violeta, Odette Scharenborg, Tomoki Toda
Comments: Accepted to ICASSP 2022.
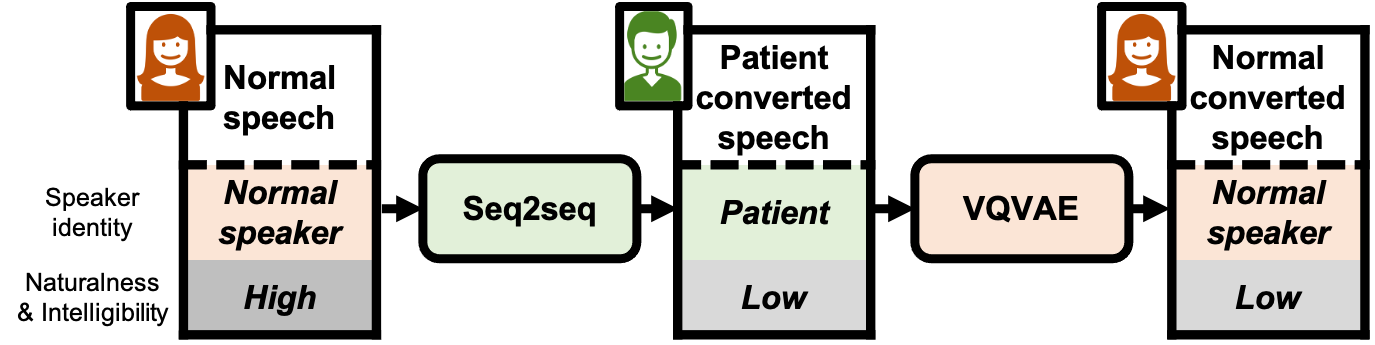
Abstract: We present a voice conversion framework that converts normal speech into dysarthric speech while preserving the speaker identity. Such a framework is essential for (1) clinical decision making processes and alleviation of patient stress, (2) data augmentation for dysarthric speech recognition. This is an especially challenging task since the converted samples should capture the severity of dysarthric speech while being highly natural and possessing the speaker identity of the normal speaker. To this end, we adopted a two-stage framework, which consists of a sequence-to-sequence model and a nonparallel frame-wise model. Objective and subjective evaluations were conducted on the UASpeech dataset, and results showed that the method was able to yield reasonable naturalness and capture severity aspects of the pathological speech. On the other hand, the similarity to the normal source speaker's voice was limited and requires further improvements.
Proposed method
Dataset
We used the UASpeech dataset. We used data of all 13 control speakers as the source speakers, and 6 dysarthric speakers. We chose 2 dysarthric speakers from each intelligibility group (high: M08, M10; mid: M05, M11; low: M04, M12) as test speakers.
Speech Samples
Note: we only show 1 dysarthric speaker from each intelligibility group in the following demo.
Transcription: "Command"
Control Speaker
Input speech
Dysarthric speaker (intelligibility level)
Seq2seq (VTN)
Seq2seq (VTN) + Nonparallel frame-wise model (VAE)
Dysarthric speaker reference speech
CF02
M04 (low)
M05 (mid)
M08 (high)
CM08
M04 (low)
M05 (mid)
M08 (high)
Transcription: "Backspace"
Control Speaker
Input speech
Dysarthric speaker (intelligibility level)
Seq2seq (VTN)
Seq2seq (VTN) + Nonparallel frame-wise model (VAE)
Dysarthric speaker reference speech
CF02
M04 (low)
M05 (mid)
M08 (high)
CM08
M04 (low)
M05 (mid)
M08 (high)
Transcription: "Delete"
Control Speaker
Input speech
Dysarthric speaker (intelligibility level)
Seq2seq (VTN)
Seq2seq (VTN) + Nonparallel frame-wise model (VAE)