Investigating Factors Related to the Naturalness of Synthesized Unison Singing
Paper: To be uploaded
Authors: Kaito Nishizawa, Ryuichi Yamamoto, Wen-Chin Huang, Tomoki Toda
Comments: Accepted to ICASSP 2025.
Abstract: Singing voice synthesis (SVS) technology has progressed rapidly in recent years. However, vocal ensemble synthesis has not yet been widely explored. In this work, we focus on unison singing, which is to have several singers singing the same melody together. Our goal is to understand what acoustic properties affect the naturalness of the synthesized unison singing. We utilize NNSVS, an SVS toolkit that allows us to manipulate individual acoustic features, including timing, f0, and spectrum features, in a fully data-driven manner to investigate their effect in unison singing synthesis. Through listening tests, it was shown that the fluctuation in timing and f0 is an important factor in synthesizing natural unison singing. Furthermore, we discovered the potential to generate unison singing using an SVS model trained only with a single singer dataset.
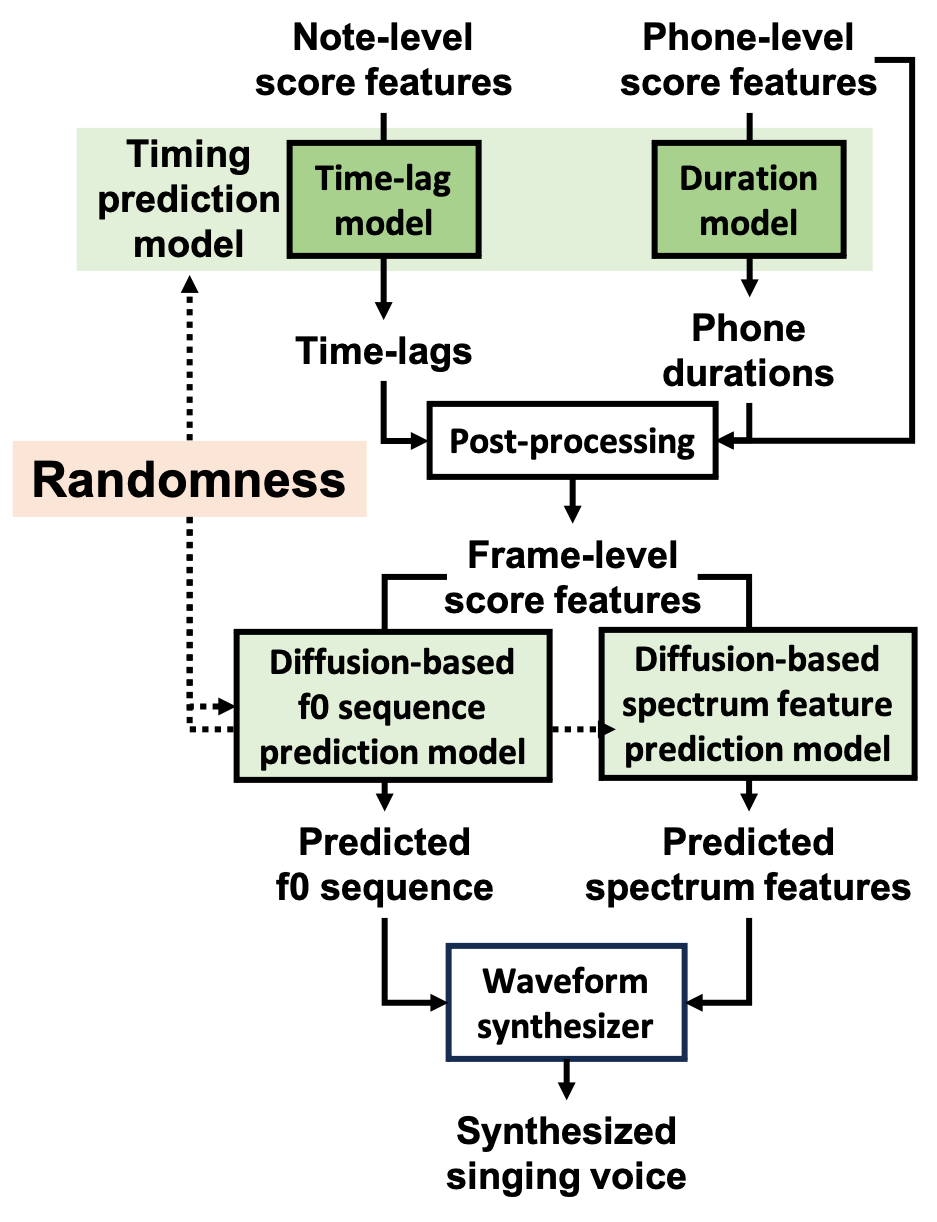
The SVS model used in this work
Experiment 1: factors to the naturalness of unison singing
timing
f0
spectrum
naturalness MOS
sample
-
-
-
1.56 ± 0.15
V
-
-
3.94 ± 0.11
-
V
-
3.80 ± 0.11
-
-
V
1.66 ± 0.16
V
V
-
4.10 ± 0.10
-
V
V
4.04 ± 0.11
V
-
V
4.06 ± 0.11
V
V
V
4.14 ± 0.11
Experiment 2: influence of the number of solo singing samples