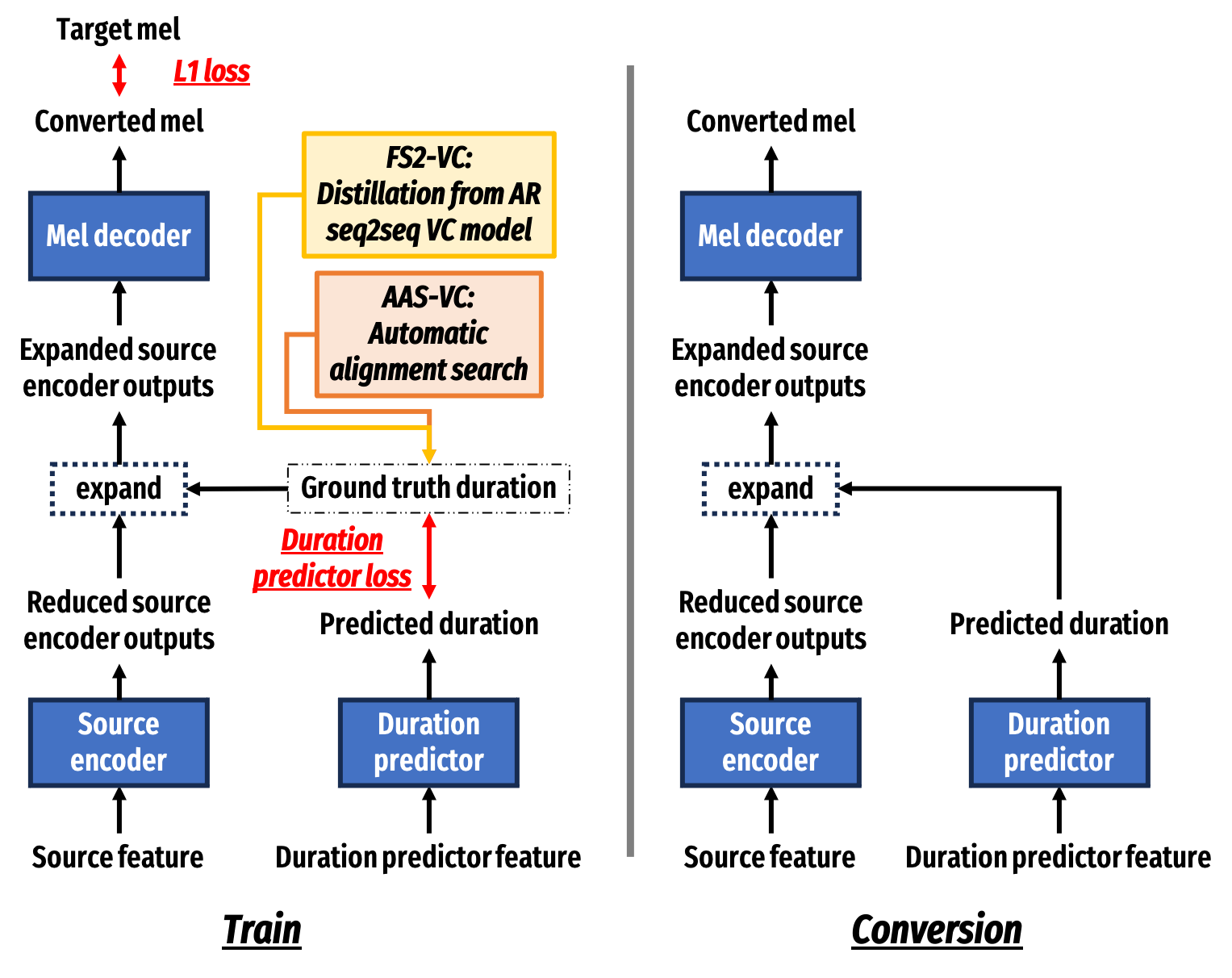
Abstract: Non-autoregressive (NAR) sequence-to-seqeunce (seq2seq) models for voice conversion (VC) is attractive in its ability to effectively model the temporal structure while enjoying boosted intelligibility and fast inference thanks to NAR modeling. However, the dependency of NAR seq2seq VC models on ground truth durations extracted from an AR model greatly limits its generalization ability to smaller training datasets. In this work, we first show the existence of the above-mentioned problem by varying the training data size. Then, we present AAS-VC, a non-AR seq2seq VC model based on automatic alignment search (AAS), which serves as a proper inductive bias to provide the required generalization ability for low resource settings. Experimental results show that AAS-VC can generalize well to a training dataset of only 5 minutes. We also conducted ablation studies to justify several model design choices. The audio samples and implementation are available online.
Proposed method
Dataset
We conducted all our experiments on the CMU Arctic database.
A male speaker (bdl) and a female speaker (clb) were chosen as source speakers, and a male speaker (rms) and a female speaker (slt) were chosen as the target speakers.
Compared systems
Source, Target: Natural speech of the source and target speakers.
Analysis-Synthesis: Analysis-synthesis samples from the Parallel WaveGAN vocoder.
FS2-VC: FastSpeech2 based non-AR seq2seq VC model, with ground truth durations extracted from a Voice Transformer Network (VTN, a.k.a. Transformer-VC), an AR seq2seq VC model. To simulate FS2-VC with different ground truth duration quality, we use two variants:
FS2-VC (No PT): FS2-VC with ground truth duration extracted from a VTN trained from scratch.
FS2-VC (PT): FS2-VC with ground truth duration extracted from a VTN with TTS-style pre-training on LJSpeech (24 hrs).
AAS-VC: The proposed non-AR seq2seq VC model with automatic alignment search.
Speech Samples
Transcription: And there was Ethel Baird, whom also you must remember.
Model
Number of training utterances (duration)
clb(F)-slt(F)
bdl(M)-slt(F)
clb(F)-rms(M)
bdl(M)-rms(M)
Source
-
Target
-
Analysis-Synthesis
-
FS2-VC (No PT)
932
FS2-VC (PT)
932
AAS-VC
932
FS2-VC (No PT)
80
FS2-VC (PT)
80
AAS-VC
80
Transcription: It was introduced by Representative Dick of Ohio.
Model
Number of training utterances (duration)
clb(F)-slt(F)
bdl(M)-slt(F)
clb(F)-rms(M)
bdl(M)-rms(M)
Source
-
Target
-
Analysis-Synthesis
-
FS2-VC (No PT)
932
FS2-VC (PT)
932
AAS-VC
932
FS2-VC (No PT)
80
FS2-VC (PT)
80
AAS-VC
80
Transcription: But why continue the tirade, for tirade it was.